
Google 宣布為其生成式人工智慧 Bard 帶來功能更新,包括將擴大支援運行 Gemini Pro 模型版本至超過 40 種語言與 230 個國家和地區,其中也包含繁體中文版本,讓更多使用者能夠和 Bard 共同協作。並推出全新圖像生成功能,幫助用戶把更多創意想法(咒語?)變成一張張真實的圖片呈現在自己眼前。

針對跨語言模型和聊天機器人的指標評估機構 ─ Large Model Systems Organization(LMSYS Org)在近期分享,相較於其他類似免費或需付費的聊天機器人服務,採用 Gemini Pro 模型的 Bard 最受到受試者喜愛,並指出 Bard 展現了「令人驚艷的升級」。除此之外,在 Google 委由第三方評測機構進行的盲測評估中,與其他業界領先的免費和付費聊天機器人相比,採用 Gemini Pro 模型的 Bard 也獲選為表現最好的對話式 AI 服務之一。
Google 宣布從今天開始,Bard 會支援超過 40 種語言。只要用戶在回應的下方欄位點擊「G」圖示,Bard 就會協助評估在網路上是否能找到相關資訊來驗證回覆中的陳述內容。如果回覆的內容有找到相關資訊參考驗證,使用者只需要點擊具有醒目提示的字詞或語句,就可以進一步看到在 Google 搜尋結果中持相同或相反意見的有關資訊。
另一個現在很多朋友喜愛的 AI 功能就是圖片生成,只要輸入”咒語” ,就能把想像的畫面變成圖片呈現,現在 Bard 也能支援圖片產生的功能,雖然目前僅支援英文咒語,但是不需要另外付費。這項全新功能採用了我們升級版的 Imagen 2 模型,可以生成出兼顧品質與效率、高品質且逼真寫實的輸出成果。只需要給 Bard 一段語言描述,例如「創造一張狗在衝浪板上衝浪的圖片」,Bard 就會生成出客製化且種類多元的圖片,來把腦中的創意化為現實。
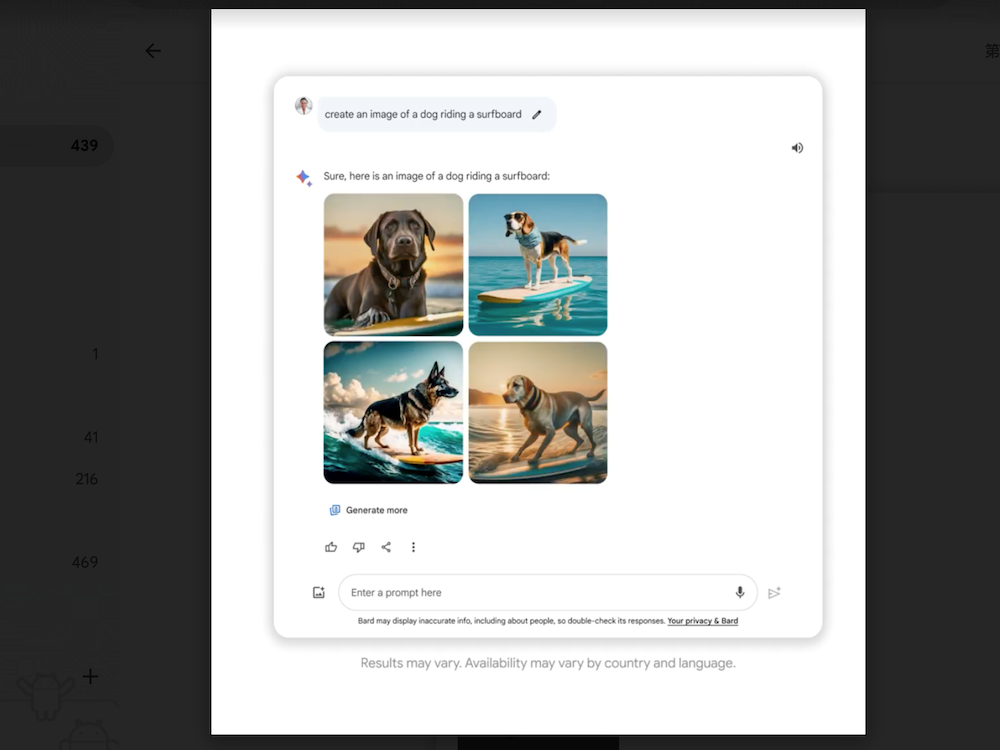
Google 也表示秉持他們的 AI 原則,圖像生成功能也是以負責任的方式進行開發設計。例如,為了確保 Bard 生成的圖像,可以和原創藝術家的作品有明顯區別,Bard 會使用 SynthID 工具,在生成圖像的像素中,嵌入數位可識別的浮水印來協助區別。
除此之外,還會透過在訓練資料安全性的技術防護與投資,希望能針對暴力、攻擊性與內含冒犯或露骨內容加以限制。Google 也會透過篩選與過濾技術,來避免針對特定或知名人物的圖片生成,並持續投資開發新技術來提高自身模型的安全性與隱私保護。










